


Today’s tools support and encourage the duplication of data. Let’s assume user A obtains a document from the enterprise storage and sends it as an attachment by email to user B who stores it on a laptop. This everyday scenario shows how easily files are duplicated. The document file is not only in the enterprise storage, but also in A’s sent box, in B’s inbox, and on B’s laptop, possibly twice if it is in the target folder selected by B as well as in the download folder.
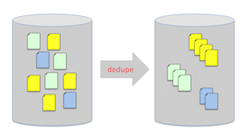
In eDiscovery, it is desirable to group duplicates before reviewing. This grouping is often called deduplication, which must not be confused with deduplicating in order to save storage space. In this latter case, identical disk blocks of files are stored only once. Deduplication for eDisovery is more challenging.
The notion of duplicates in the context of eDiscovery is quite tricky. When looking at the file described above, there are a number of differences between the copies: file path, creation date, file owner, last modified and last access date, etc. For certain forensic information needs, it may matter who accessed the document and when. However, in early case assessment it is desirable to group as many duplicates as possible to speed up a first review of possibly relevant data. This is why eD-MCS supports different definitions of duplicates as well as relevance ranking, in order to review the most relevant documents first.
